


If you have not yet read Blogs 1 and 2 of Navigating the Conversational Analytics Maze, I would highly recommend you do so, since most of the examples and concepts in this post will require that context to understand.
Welcome to our final installment of Navigating the Conversational Analytics Maze. Thus far, we have looked at Accuracy and Precision, two machine learning (ML) model metrics whose equations can be seen below:
Accuracy=Total Correct Guesses/Total Guesses
Precision=Correct Positive Guesses/Total Positive Guesses
These formulas and their inputs are more easily understood when accompanied by a Confusion Matrix: a grid that helps visualize the labels that artificial intelligence (AI) predicted were correct versus the labels that were correct.
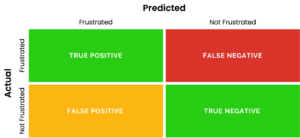
For the last couple of weeks, we have been using the example of an ML model tasked with analyzing business-to-customer interactions and determining whether any customers are expressing frustration on calls. If the model determines a customer was frustrated, it will label the call as registering positive for frustration. Any callers it deems are not frustrated will be labeled as negative for frustration.
In week 1, we learned that it is rare for customers to express frustration on a call (less than one in ten), which makes it impractical to have a human sift through hundreds, or even thousands of conversations to find such a small subset of calls. Consequently, AI becomes the natural tool for the job; however, if a company is trusting an AI-powered conversational analytics product to identify the root cause of lost customers and revenue, it is imperative that the AI is heavily refined and tested.
Why is it so important to find frustrated callers? Studies from Online Reputation Management have shown that just one negative online review can result in up to 30 lost customers for a business. This explains why Cornell professors found that a one star increase in online ratings can lead to up to 39% more revenue. If a company is to trust an AI-powered conversational analytics product to identify the root cause of lost customers and revenue, it is critical for the AI to have been expertly built and tested. Unfair as it may seem for less than one in ten customers to have such a dramatic influence on business, it exemplifies why noticing and making amends with this subset of customers is so vital.
To accurately assess our frustration-finding friend, we need to measure how well it can find frustrated callers. We already saw why Accuracy and Precision are insufficient to grant a wholistic view of this kind of performance. Accuracy is determined based on total guesses, so even a broken model that always guesses “not frustrated” could have an accuracy greater than 90% on our unbalanced data. Moreover, Precision only grades our model’s positive labels, meaning that it isn’t concerning itself with how many frustrated callers we are missing. This makes way for the star of today’s show: Recall.
Introducing Recall: The Key to Understanding Missed Opportunities
I am confident that, up until now, most readers had some intuition of what Accuracy and Precision were. I am also going to step out on a limb and assume that very few readers have heard about Recall. If that’s you, don’t fret.
As I mentioned previously, we are looking for something to help us gauge how well our model can find frustrated callers. In more technical terms, we need a metric that will heavily penalize False Negatives: when an AI model incorrectly labels a frustrated/dissatisfied caller as not frustrated.
Let’s resurface a view from last week:


These are the hypothetical results of a supposedly refined model analyzing a set of 100 calls, ten of which contain frustrated callers. Its accuracy and precision are 92% and 100%, respectively. This means whenever the model labeled a call, it was correct 92% of the time (accuracy), and, whenever it labeled a caller as frustrated, it was right 100% of the time. However, those with a keen eye will be suspicious looking at the above matrix, especially when they see the big red box with False Negative.
Remember, we want to know how good our model is at finding frustrated callers. To do that, we simply divide how many correct positive labels our model made (True Positives) by the total amount of frustrated callers in the data set. The general equation is:
Recall=Correct Positive Guesses/All Positive Labels
“All Positive Labels” simply means all positive cases of frustration (or whatever you want your AI model to find). For the above confusion matrix, our recall would therefore be:
Recall=2 True Positives/10 Frustrated Callers=20%
That’s a lot worse than the 92% and 100% we were throwing around earlier. But what does it mean? Well, in short, it means that for every frustrated caller we find, there will be four more frustrated callers that we don’t find. For our example, assuming four out of the eight frustrated callers we didn’t find went on to leave a bad review, and remembering that just one negative review can lead to 30 lost customers, this equates to 120 potentially lost customers. Clearly, the repercussions of mislabeling something like frustration are quite great.
When it comes to shopping for quality AI-powered conversational analytics tools, there are a couple of questions you can ask yourself to understand what kind of performance you need to see.
- What do I need the AI to find?
- Would I rather be safe than sorry?
There are instances where precision and recall might be inversely related. For our frustration-identification example, perhaps you would rather be safe than sorry, meaning you would be okay with having more False Positives (lower precision) to have fewer False Negatives (higher recall). There are instances where having an AI model label correctly is more important than having the model find every instance of said label. In this case, having a higher precision would matter more than recall.
Here at Marchex, we are no strangers to building robust AI-powered solutions. In fact, one of our customers, Geeks on Site, saw over $50,000 worth of sales rescued in one month by a tool built to identify and send alerts whenever high-potential sales opportunities were marked as incomplete. You can bet that this tool had exceptional recall, since it successfully identified countless high-quality leads who were on the cusp of converting. This tool is but one example of the many AI and generative-AI powered products that Marchex has available today.
I hope that you have enjoyed this somewhat brain-bending series, and I hope that it will be of use to you as you now know the strengths and weaknesses of accuracy, precision, and recall, and how these metrics collectively unveil the caliber of an AI model.







